Appearance
1. 误差分析
假设训练一个猫图片分类的模型,目前有了90%的准确率。错误的样本中,有的是将狗认为是猫,有的是由于图片太模糊,还有的是其它原因。那么究竟向哪个方向去改进是收益比较高的呢?可以选取一部分错误数据进行统计分析,然后比较各个出错原因的比例。对于那些占比较高的错误原因,是比较好的努力方向。例如错数据中有50%都是因为图片模糊,那么去努力改进模型对模糊图片的处理能力,是比较值得去做的。
2. 样本标注错误
有些时候,训练集里的部分样本存在着标注错误。例如一张小狗的图片,却被标记为是猫。如果样本量比较大,而标记错误是随机的且占比较少,那么可以不用去考虑修复,模型依然可以很好地适应。深度学习算法虽然对随机误差不敏感,但是对于系统性的误差,则会学习到错误的信息。例如如果白色的狗狗图片都被标注成了猫,则最后模型会认为白色的狗狗是猫。
那么如果开发集和测试集存在标注错误呢?可以在误差分析的时候同时统计样本是否有标注错误。如果由于标注错误导致的开发集或测试集误差较高,那么就需要去修复这些错误的标注。反之,可以暂不考虑,或者不作为重点考虑。
3. 数据不匹配问题
有些情况下,会存在数据不一致的问题。例如训练一个猫图片的分类模型,样本有20W是网上抓取的高清图片,还有1W用户拍的模糊的图片。在这种情况下,要保证开发集和测试集的数据分布一直,训练集的数据和开发集的数据分布可以不一致。然后要从训练集中划分出一部分作为训练开发集。如图所示:
dev test
↓ ↓
+----------------+----+---+---+
| | | | |
+----------------+----+---+---+
↑ ↑
train train-dev然后分析各个阶段的误差,来分析模型的改进之处,如下图所示:
Human-Level Error ---
↑
| avoidable bias
↓
Train Error ---
↑
| variance
↓
Train-Dev Error ---
↑
| data mismatch
↓
Dev Error ---
↑
| degree of overfitting to dev set
↓
Test Error ---4. 迁移学习
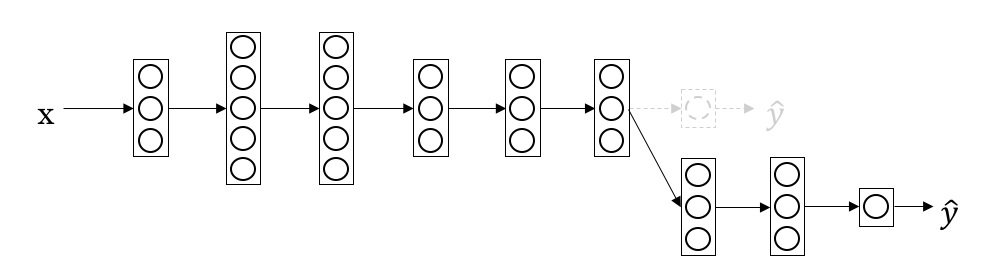
即将已经训练好的模型的参数应用到新模型的训练上。因为很多低层次的特征是相对通用的,例如边缘检测等。通常的做法是将训练好的模型的输出层去掉,然后后面加上一层或多层网络结构接着训练。如图所示:
5. 多任务学习
例如要训练一个自动驾驶系统,需要识别车辆、行人、信号灯、路标等各种标识。可以对每一种需要识别的物体都分别训练一个模型来进行识别。但更好的做法是通过一个模型来识别这多种物体。多任务学习常用语计算机视觉领域。
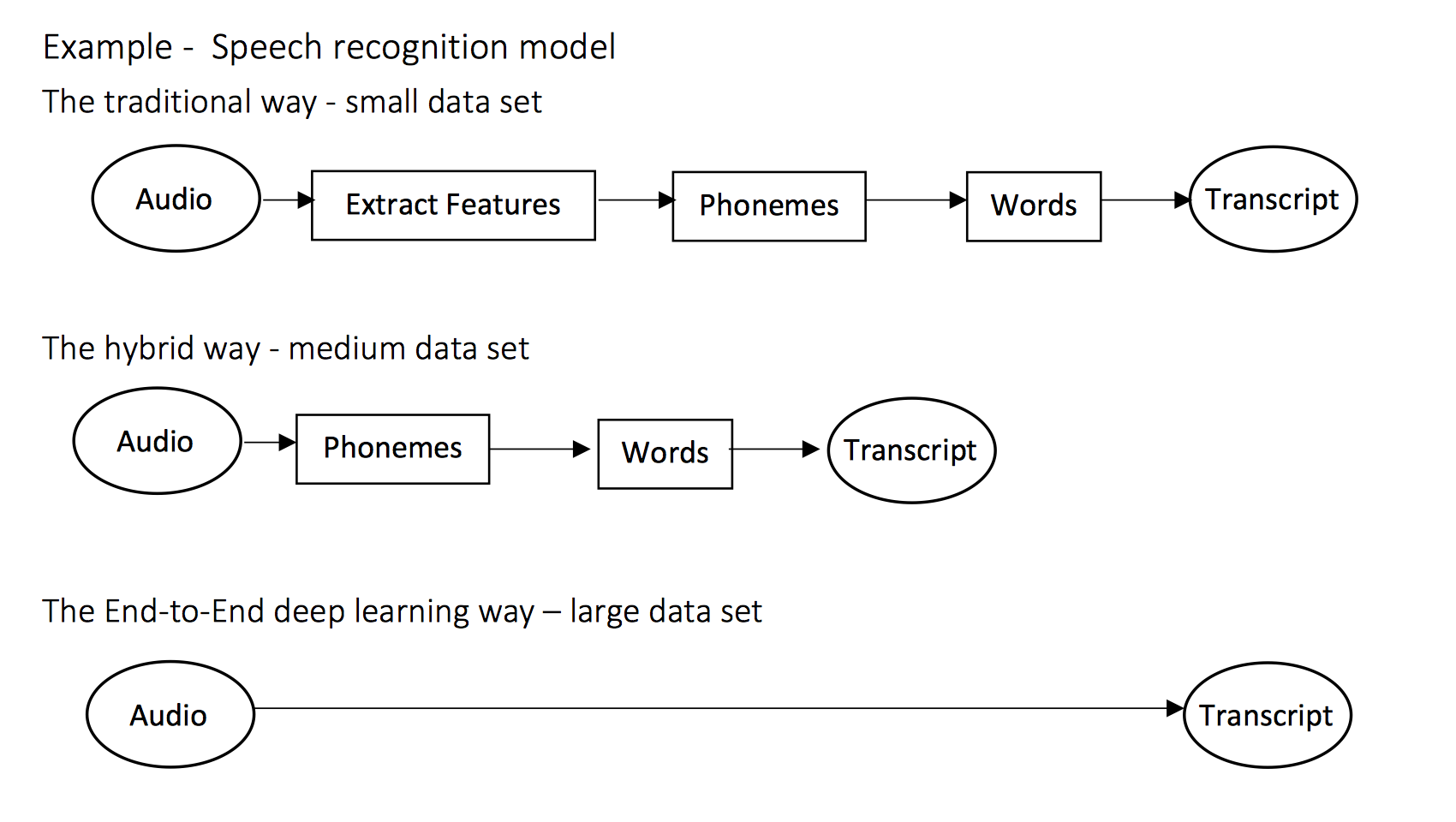
6. 端到端的深度学习