Appearance
1. 超参数
到目前为止,已经涉及到了许多个超参数:
- 学习速率
- Momentum优化算法的
- Adam优化算法的
- 网络层数
- 每个隐藏层的神经单元个数
- 学习率衰减
不同的超参数的重要性也不尽相同,例如:
极为重要,需要不断调试 ,神经单元个数,以及 也需要进行适当的调试 - 其次是
则通常使用默认值
2. 超参数取样原则
(1)网格取样和随机取样
如下图所示,在选择超参数的时候,有两种取样方式:网格和随机。
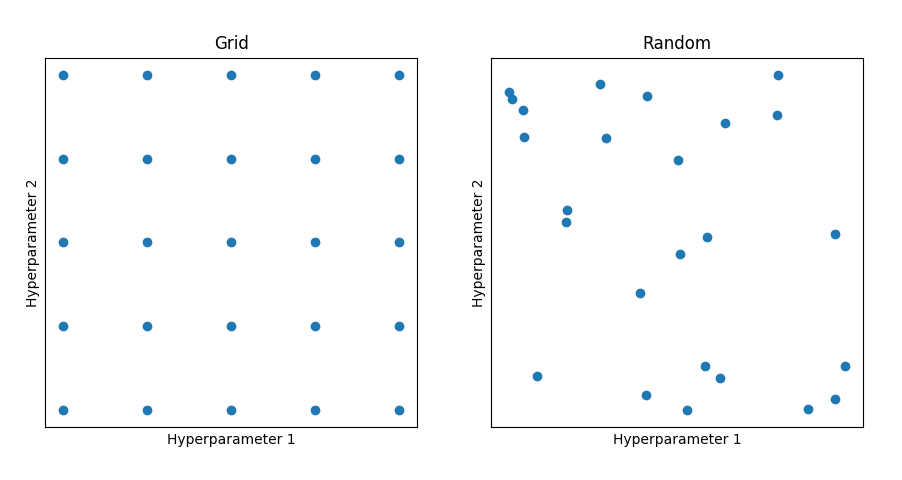
网格取样存在的一个问题是:如果超参数1比较重要,而超参数2不那么重要,那么在尝试了25个点之后,超参数1只取了5个值进行尝试,显然是比较浪费的。所以更好的方式是进行随机取样,从而尝试重要超参数的更多的可能值。
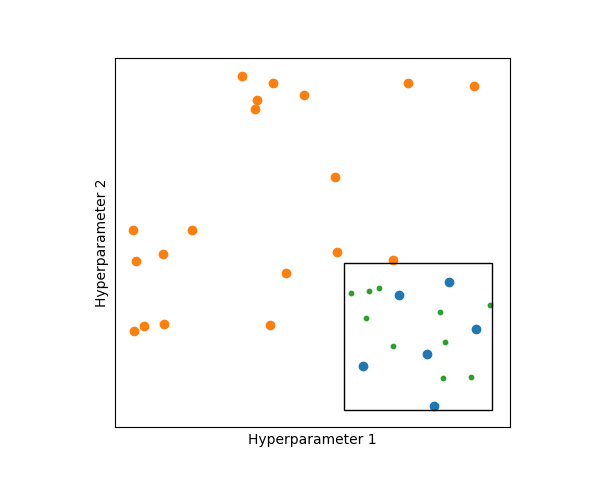
(2)范围由粗到细
如图所示,最开始选择较大的范围对超参数进行取样(图中橙色和蓝色的点),然后针对表现较好的取样点(蓝色的点)圈定更小的范围,生成更多的取样点(绿色的点)。
3. 超参数范围选择
针对不同的超参数,应当选取不同的策略来进行范围选择。
例如对网络层数
对于
4. 超参数调试方式
- 在没有足够多计算资源(CPU、GPU)的情况下,针对一个模型进行不断调试,逐步完善。(熊猫方式)
- 在计算资源充足的情况下,使用不同的超参数进行尝试,同时训练多个模型,从条选取表现好的模型。(鱼子酱方式)
5. Batch Normalization
对于神经网络中的某一层:
特别地,当
这里
Batch Norm(简称BN)可以显著加速训练,并能使模型有更好的适应性,即当特征的数值分布发生变化时,通过BN,可以使它们的相对分布依然保持不变,这样即使训练数据和预测数据的特征数值不同,模型也能够很好的适应。此外,BN还有轻微的正则化效果。
在训练过程中使用BN,那么在预测过程中,每次处理一条数据,如何应用BN呢?在训练过程中,针对第
6. Softmax
针对二元分类问题,最后一层的激活函数可以使用Sigmoid,但是针对多分类问题,常用的是Softmax。假设一共要分成