Appearance
1. 词汇表示
(1)One-hot
假设有一个词汇表,V=[a, arron, ..., zulu, UNK],则可以用
这样的表示存在着一个很大的问题,就是把每个词都孤立起来了,从而导致算法对相关词汇的泛华能力不够。例如模型已经学到了一个句子:
I want a glass of orange ( juice ).
但是如果遇到另一个类似的句子:
I want a glass of apple ( ? ).
很明显这里很有可能也是 juice,但是由于模型不知道 orange 和 apple 的相似关系,因此难以做出判断。这是由于 one-hot 的表示方法,导致任意两个词向量的内积都是0,因此无法得知词与词之间的关系。
(2)Embedding
Embedding 是使用词的特征来表示一个词。例如:
| man | woman | king | queen | apple | orange | |
|---|---|---|---|---|---|---|
| gender | -1 | 1 | -0.95 | 0.97 | 0.00 | 0.01 |
| royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 | 0.00 |
| age | 0.03 | 0.02 | 0.7 | 0.69 | 0.03 | -0.02 |
| food | 0.09 | 0.01 | 0.02 | 0.01 | 0.95 | 0.97 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
假设一共有300个特征,则每个词可以用一个300维的向量来表示。将这些词在向量空间中进行可视化,则可以发现如下的分布(使用t-SNE算法降维可视化):
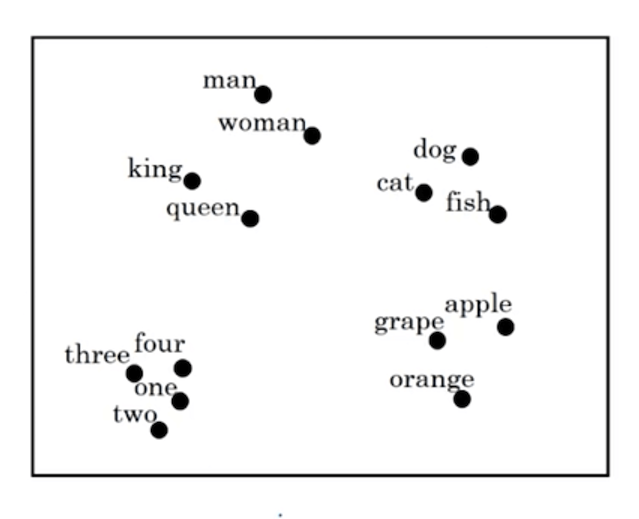
2. 词嵌入的特性
词嵌入(Word Embedding)的一个很重要特性就是类比推理。例如下面的词汇表:
| man | woman | king | queen | apple | orange | |
|---|---|---|---|---|---|---|
| gender | -1 | 1 | -0.95 | 0.97 | 0.00 | 0.01 |
| royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 | 0.00 |
| age | 0.03 | 0.02 | 0.7 | 0.69 | 0.03 | -0.02 |
| food | 0.09 | 0.01 | 0.02 | 0.01 | 0.95 | 0.97 |
假设每个单词用一个四维的向量来表示。用
在已知
对于两个向量
因此通过计算
3. 嵌入矩阵
假设词库中有10000个词,每个词的embedding是一个300维的向量。则整个词库的嵌入矩阵表示为:
令
4. Word2Vec
这部分主要讲解Word2Vec的skip-gram模型(另外一种模型是CBOW)。
假设我们有这样一个句子:I want a glass of orange juice to go along with my cereal. 在skip-gram模型中,需要从句子中抽取出上下文(context)和目标词(target)的配对,从而构建出一个监督学习。
从句子中选取一个词,然后这个词的前后
| Context | Target |
|---|---|
| orange | juice |
| orange | glass |
| orange | want |
| … | … |
然后使用这些词对构建一个监督学习模型。假设词汇表中有10000个单词,需要的词嵌入为300维,则网络的输入层有10000个节点,隐藏层有300个节点,输出层有10000个节点。我们所需要的嵌入矩阵也就是从输入层到隐藏层的权重矩阵。
输入层输入的是context的one-hot向量,即
5. 负采样
假设同样的句子:I want a glass of orange juice to go along with my cereal. 从句子中选取一对context和target作为正样本,然后使用context,并从词典里随机选取其他词和context组成单词对,作为负样本。例如:
| Context | Target | y |
|---|---|---|
| orange | juice | 1 |
| orange | king | 0 |
| orange | book | 0 |
| orange | the | 0 |
| orange | of | o |
| … | … | … |
这里需要注意的是,虽然of出现在orange附近,但是由于最初我们选取的是orange和juice作为正样本,所以我们认为orange和of是一个负样本。也就是说,即使从词典中随机选取的词刚好出现在context附近,我们也认为是一个负样本。
接下来通过这些样本来构建一个监督学习。在使用skip-gram模型的时候,从隐藏层到输出层会涉及到大量的参数,并且最后的softmax计算也非常耗时。在使用负采样的时候,输出层不再采用softmax,而是使用sigmoid函数。假如有1个正样本和5个负样本,则输出层一共有六个节点,相当于是六个逻辑回归问题。
6. GloVe
即Global Vectors for Word Representation,是另外一种词嵌入算法。
定义
其中
7. 情感分类
文本的情感分类是一个很常见的问题,例如对餐厅的评分:
| x | y |
|---|---|
| The dessert is excellent. | ★★★★☆ |
| Service was quite slow. | ★★☆☆☆ |
| Good for a quick meal, but nothing special. | ★★★☆☆ |
| Completely lacking in good taste, good service, and good ambience. | ★☆☆☆☆ |
一种方式就是对输入每个单词的嵌入向量求均值,然后通过softmax输出评分,如图所示:
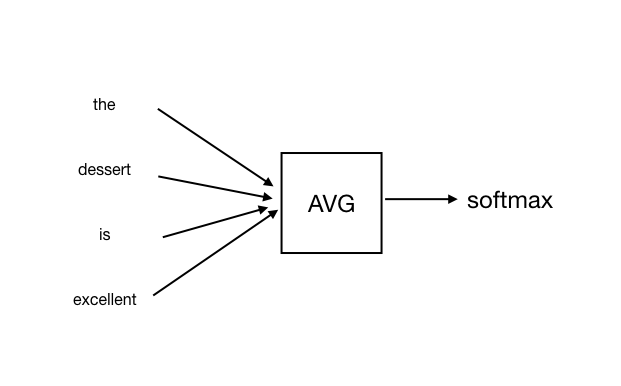
不过这个算法也存在一个很大的问题,也就是不考虑词序,会把同一个评价中,正面评价的部分和负面评价的部分相中和。
更好的方式是使用一个RNN网络来进行计算。
8. 词嵌入消除偏见
机器学习的方式可能会被用于辅助制定社会决策等,因此在这个过程中,需要避免一些不应该出现的偏见,例如性别歧视,种族歧视等。
例如:Man:Woman as King:Queen 是合理的,但是 Man:Computer_Programmer as Woman:Homemaker 则有着一些偏见的意味,其它不合理的例子还有 Father:Doctor as Mother:Nurse 等。
也就是说,由于所选取的训练文本有可能带有一些社会偏见,因此词嵌入有可能会在一定程度上反映性别、种族、年龄、性取向等方面的偏见。
相关论文可以参考 Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings.