Appearance
#MachineLearning
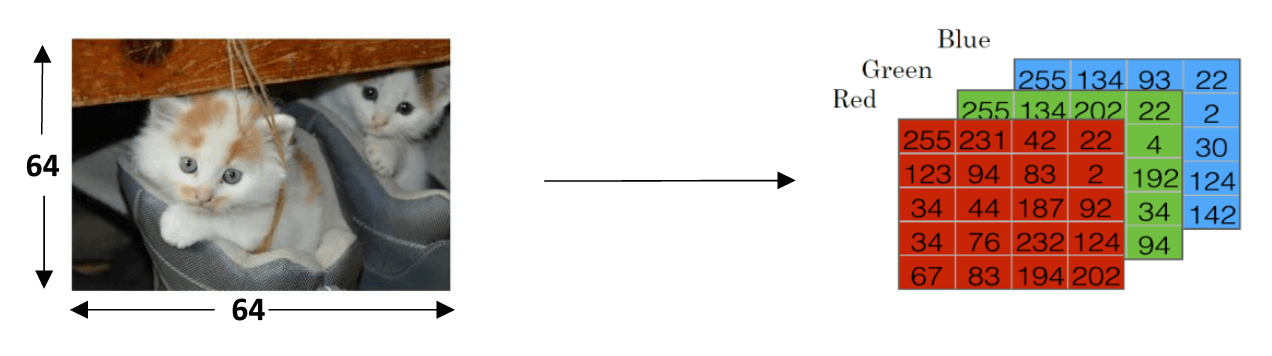
假设有一批猫和非猫的图片,要判断是否是猫。假设图片都是彩色图片,尺寸为64×64。
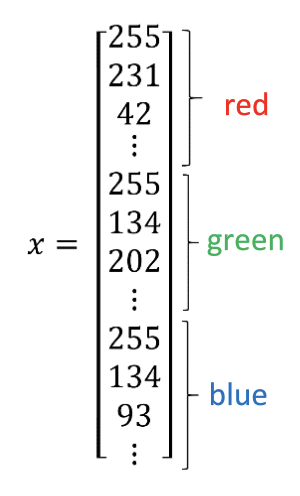
在训练的时候,将图片进行铺平展开,如下图所示:
用m表示样本的个数,nx表示特征数,则:
对于二元分类的一个样本输入(x,y),令y^=P(y=1∣x)。即y^是一个概率值。
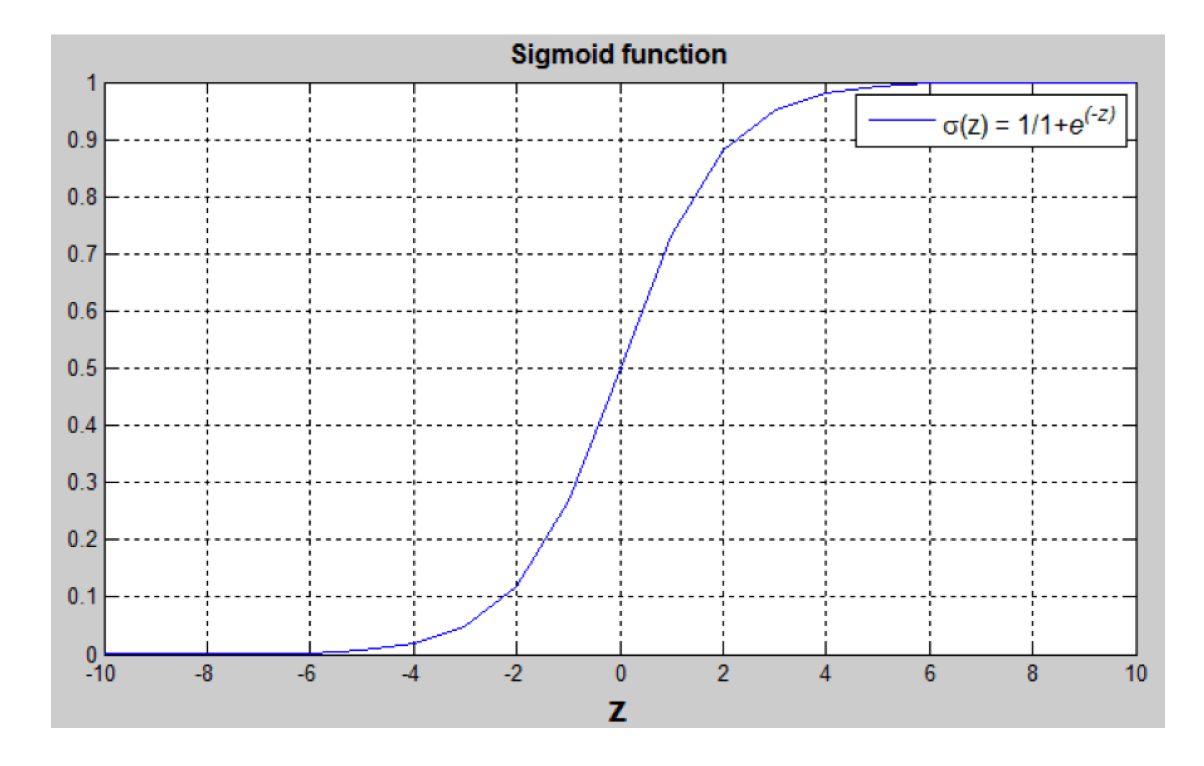
令w∈Rnx,b∈R,则y^=σ(wTx+b),其中σ为sigmoid函数,σ(z)=11+e−z。
对于一个训练样本,定义其损失函数为:
则:
整体的损失函数为:
对于一个样本,令:
因此:
对于整体:
其中 α 为学习速率。
写成向量化的形式为: