Appearance
1. 为什么需要策略
例如当你训练一个猫图片的分类器,目前已经达到了90%的准确率,如果想进一步提高准确度,可能有如下方法:
- 收集更多的训练数据
- 收集更多种不同姿势的猫的图片以及负样本,增加样本的多样性
- 增加模型的训练时间
- 使用其它更好的优化算法
- 使用更大或者更小的神经网络
- 增加Dropout
- 添加L2正则化
- 调整神经网络结构(激活函数、隐藏单元数量等)
- ……
也就是说,在优化一个系统的时候,可能有多种不同的选择。但是如果选择了错误的方向,会导致结果没有很大的改进,甚至变得更差。因此需要更加快速有效的方法来判断哪些方向是靠谱的,是值得去尝试的。
2. 正交化
在调整一个系统的时候,往往会有多种选择。如果同时选择多种方法,很有可能会导致意想不到的结果。所谓正交化,就是一次只选择一种方法,观察效果。例如在训练一个神经网络的时候,大致流程是:
- 损失函数拟合训练集
- 损失函数拟合开发集
- 损失函数拟合测试集
- 在真实场景下的表现
针对其中某一步,如果发现效果不理想,则可以有针对性的选择改进的方法,从而使得最终达到好的效果。
例如,如果在训练集上表现不理想,那么可以通过使用更大的网络,或者改进优化算法。如果在开发集上表现不理想,则可以通过添加正则化,或者收集更多的训练数据。如果在测试集上表现不理想,则可以增大开发集。如果在前面的结果都比较理想,但是在真实场景下表现较差,则需要考虑调整验证集,或者调整损失函数等。
也就是说,首先要分析出结果不理想的原因所在,然后对症下药。
3. 单一评估指标
(1)F1 Score
假设一个猫图片分类器的模型,可以有precision和recall两个指标来衡量:
- precision:预测是猫的图片中,有多少真的是猫
- recall:所有猫的图片中,有多少预测是猫
即:
| Actual 1 | Actual 0 | |
|---|---|---|
| Predict 1 | True Positive | False Positive |
| Predict 0 | False Negative | True Negative |
但是两个或者多个指标往往很难比较模型的好坏,因为很容易出现一个指标高另一个指标低的情况。因此最好是有一个单一的指标来对模型进行评估。例如 F1 score,通过对 Precision 和 Recall 求调和平均值:
例如有A和B两个分类器,表现如下:
| Classifier | Precision | Recall | F1 Score |
|---|---|---|---|
| A | 95% | 90% | 92.4% |
| B | 98% | 85% | 91.0% |
则通过 F1 Score 我们可以认为分类器A的表现更好。
(2)均值
另外一个例子,例如A、B、C三个算法在不同的地区有着不同的误差,如下表所示:
| Algorithm | US | China | India | Other | Average |
|---|---|---|---|---|---|
| A | 3% | 7% | 5% | 9% | 6% |
| B | 5% | 6% | 5% | 10% | 6.5% |
| C | 2% | 3% | 4% | 5% | 3.5% |
则可以通过比较均值的方法,发现算法C的平均误差最低,因此认为是最好的。
4. 满足和优化指标
有些时候很难把所有的指标归为一个统一的评估指标,例如算法同时考虑准确度和性能,如下表所示:
| Classifier | Accuracy | Running Time |
|---|---|---|
| A | 90% | 80ms |
| B | 92% | 95ms |
| C | 95% | 1500ms |
在这种情况下,虽然可以通过对准确度和运行时间加权求和来计算得出一个统一的指标,但是这样太过可以,没有明确的含义。
因此我们可以做的是,选择一个分类器,在满足运行时间要求的情况下,最大限度的提高准确度。例如运行时间不得大于100ms,那么我们就可以选择分类器B。在这种情况下,准确度就是一个优化指标,而运行时间则是一个满足指标。
也就是说,满足指标是只要满足即可,优化指标则是在满足指标的前提下,尽可能的去优化。
在有
5. 训练/开发/测试集
训练集用于训练模型,在同一个时间可能会尝试不同的思路,训练不同的模型。然后针对这多个模型,通过开发集(验证集)来选择一个表现好的模型。然后不断迭代去改善模型在开发集上的性能,最后再测试集上进行评估。
假设要开发一个猫图片的分类器,现在样本是来自世界各地的。那么在划分开发集和测试集的过程中,就需要确保每个集合都有来自世界各地的样本数据。简言之,需要开发集和测试集遵循同样的数据分布。
那么不同的样本集的大小如何确定呢?在机器学习早期的时候,样本数据量普遍偏小(例如几百个,几千个),因此可以按照训练集和测试集7:3,或者训练集、开发集、测试集比例6:2:2来进行划分。随着深度学习的发展,样本量也大大提高,往往是百万级别甚至更多的数据,在这种情况下,可以使用98%的数据作为训练集,1%的数据作为开发集,1%的数据作为测试集。
6. 指标调整
在某些情况下,需要对指标进行调整。例如一个猫图片分类器,A分类器的误差为3%,B分类器的误差为5%。看起来似乎是A分类器更好,但是A分类器可能会错误地把一些色情图片认为是猫的图片推送给用户,这是不可接受的。因此在这种情况下,需要调整误差的定义,例如:
其中:
7. 人的表现
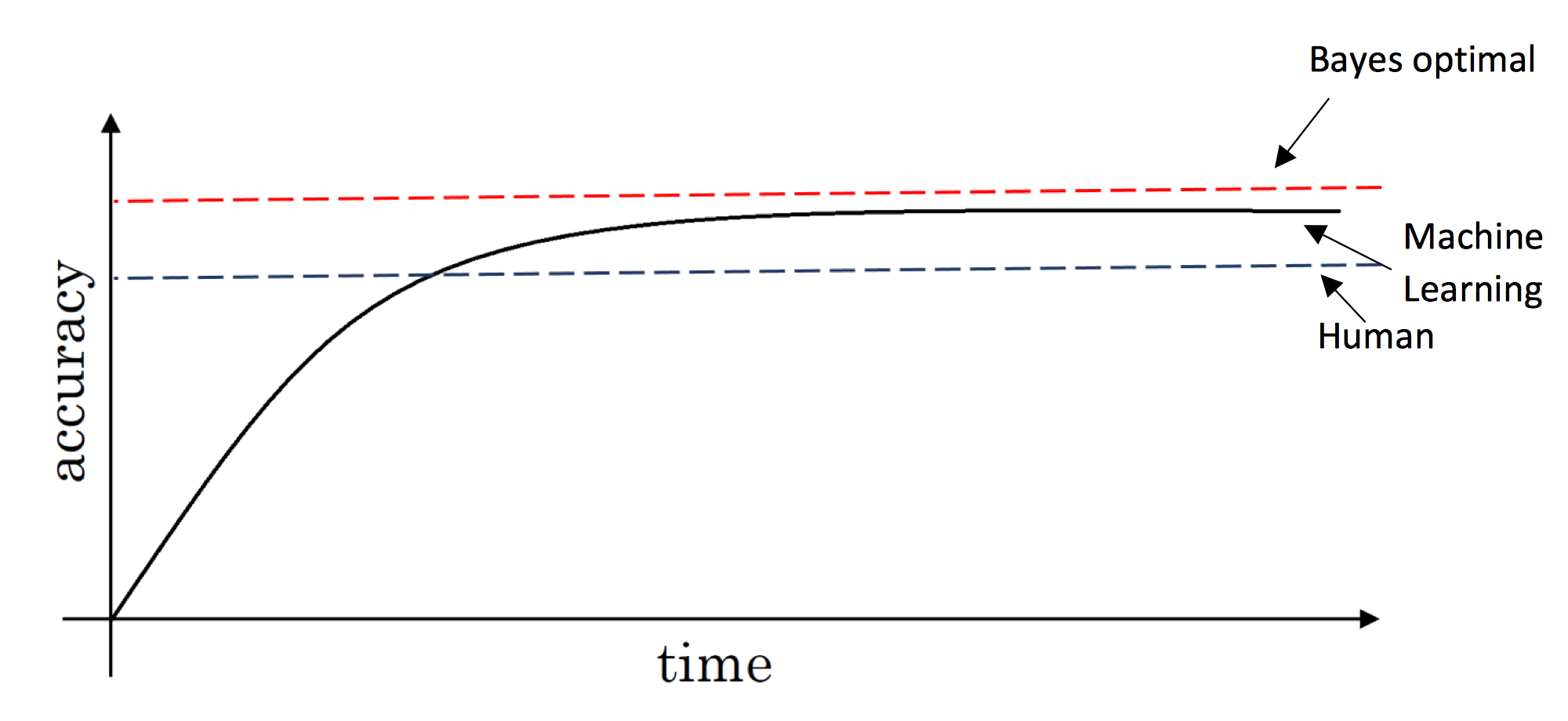
如图所示,在训练初期,模型的准确度可以很快的提高,在超过人的表现之后,增长缓慢。模型能达到的上限(理论最优)称为贝叶斯最优。
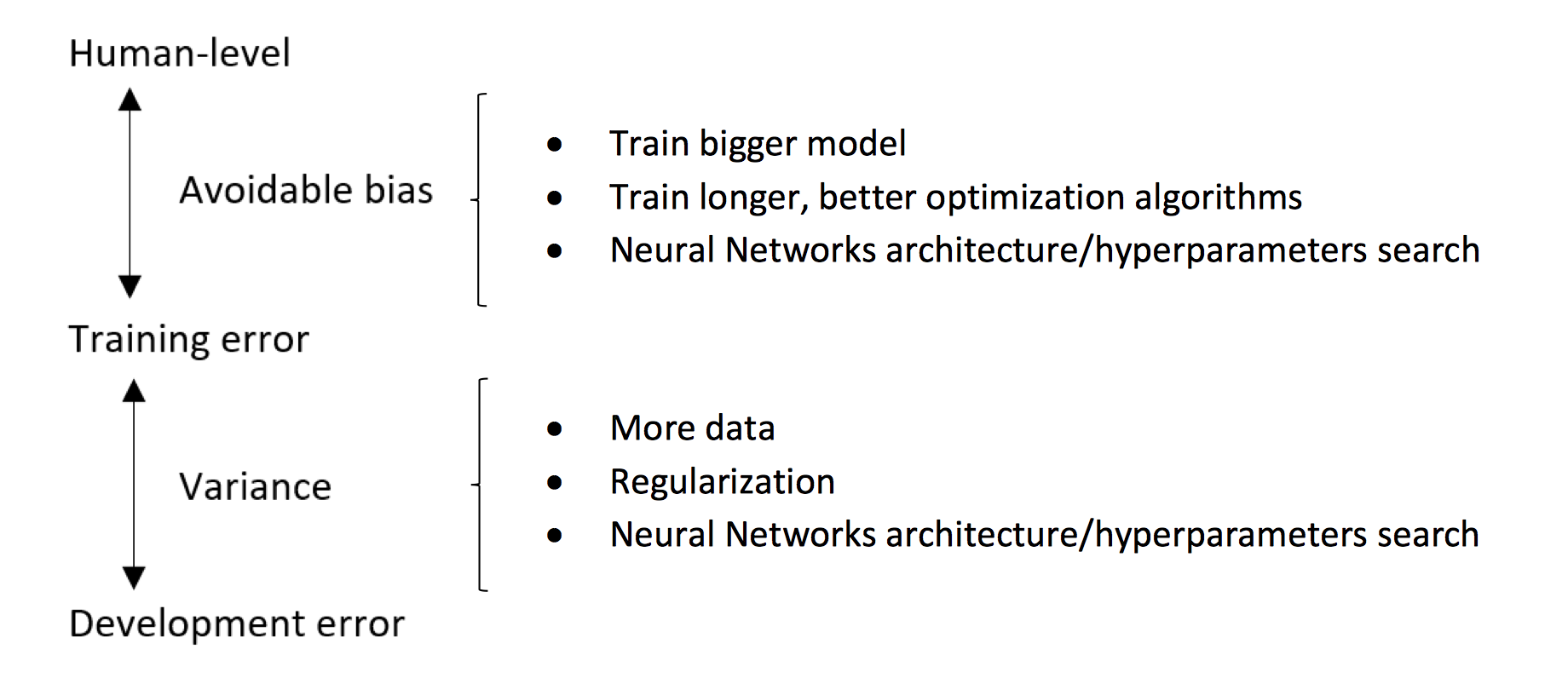
假设一个图片分类应用,人的表现误差为1%,现在训练了一个分类器,训练集误差为8%,开发集误差为10%,则这种情况下,属于偏差过大,因此应该优化训练,减少训练误差。假设人的表现误差为7.5%,那么这种情况下训练集误差和人的表现基本接近,而开发集误差较大,属于方差过大,因此应当优化开发集误差。
将训练集误差和贝叶斯最优误差之间(有时候可以用人的表现来近似代替)的差值称为可避免偏差,也就是说,我们应当优化训练过程,使得训练集误差尽可能接近贝叶斯最优误差。
8. 改善模型的表现