Appearance
1. LeNet-5
论文参考Gradient-Based Learning Applied to Document Recognition。
网络结构如图:
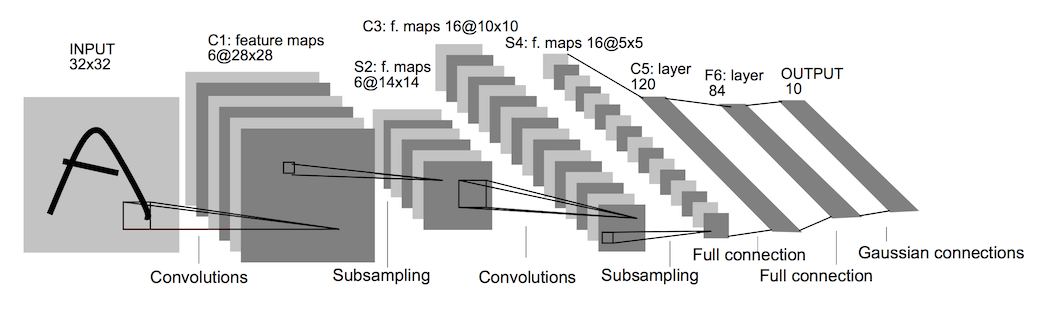
2. AlexNet
论文参考ImageNet Classification with Deep Convolutional Neural Networks。
网络结构如图:
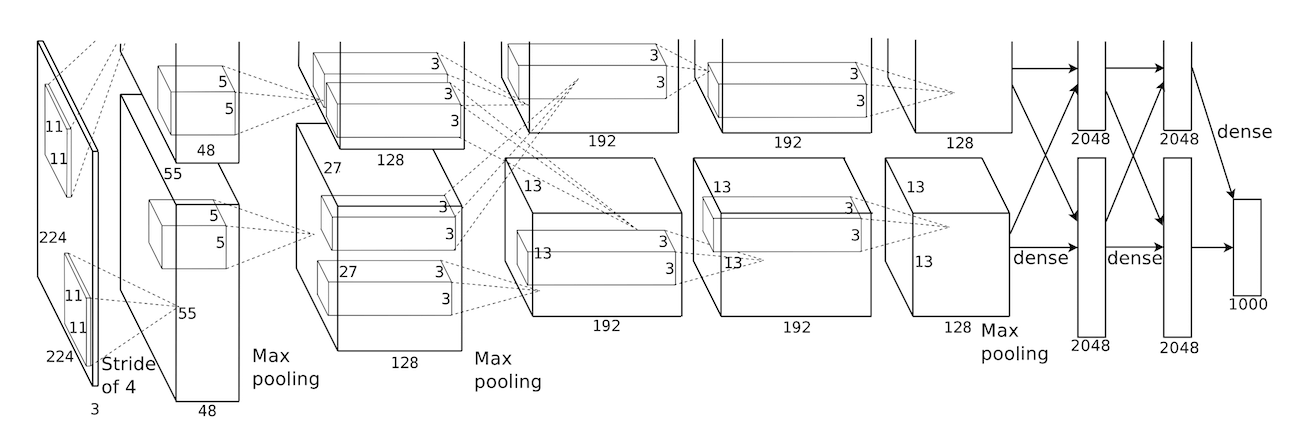
输入应该是
,论文中的图片标注有误。
3. VGG
论文参考Very Deep Convolutional Networks for Large-Scale Image Recognition。
VGG16网络结构如图:
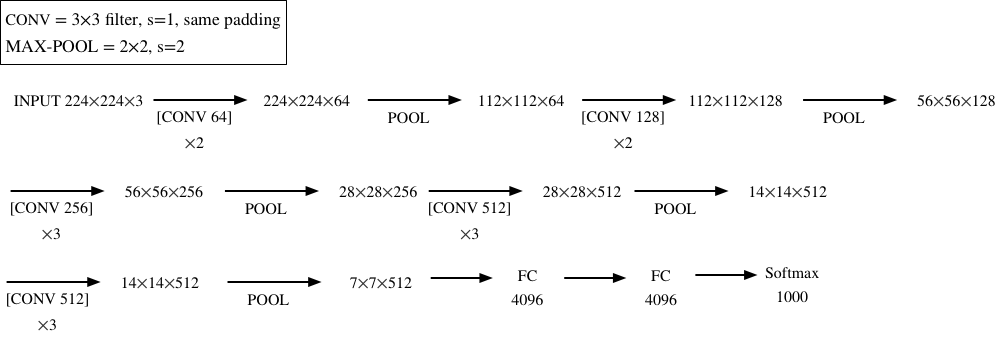
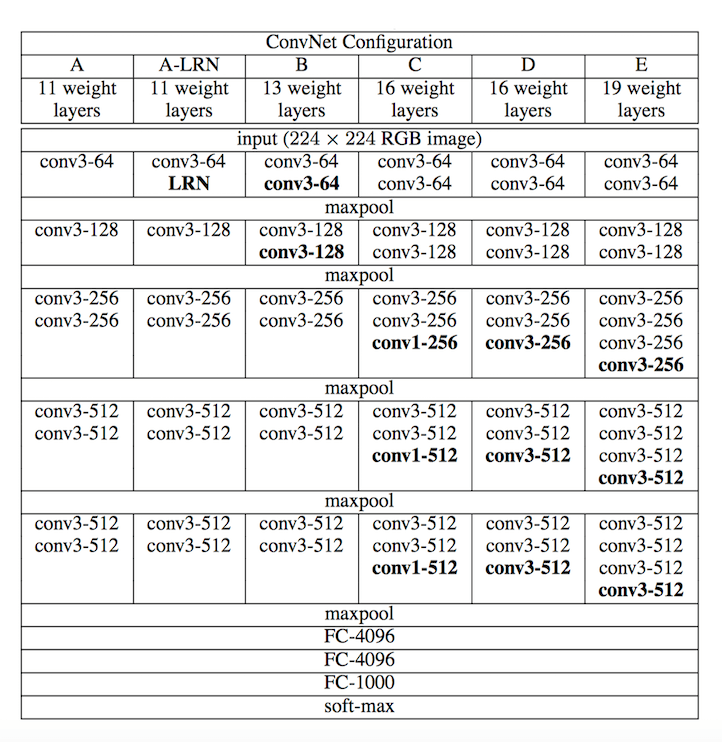
下图是论文中的网络结构表示,其中D那一列为VGG16,E那一列为VGG19。
用Keras实现VGG16代码如下:
python
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dense, Flatten
def VGG16():
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=(224, 224, 3)))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dense(4096, activation='relu'))
model.add(Dense(1000, activation='softmax'))
return model事实上,Keras已经提供了VGG16和VGG19的实现,可以直接加载训练好的模型来进行预测。例如:
python
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
model = VGG16(weights='imagenet', include_top=True)
img_path = 'cat.jpeg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
print(decode_predictions(features))
输出:
('n02123394', 'Persian_cat', 0.30621755)
('n02123159', 'tiger_cat', 0.10393093)
('n02123045', 'tabby', 0.10254558)
('n02124075', 'Egyptian_cat', 0.040458746)
('n02094258', 'Norwich_terrier', 0.018756863)