Appearance
1. 语音识别
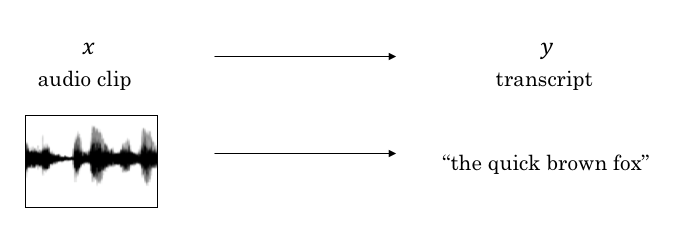
语音识别主要要做的就是把语音输入转换为文字,如下图所示:
(1)Attention Model
可以通过注意力模型来实现语音识别,如下图所示:

(2)CTC
还有一种方法是使用CTC损失函数(Connectionist Temporal Classification)来做语音识别,相关论文可以参考 Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks。主要方法是使用一个输入和输出数量相等的RNN网络结构,例如:
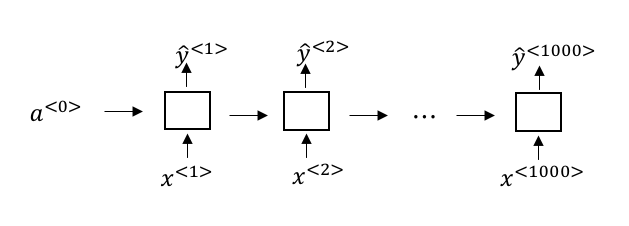
输出可能为 ttt_h_eee___ ___qqq__……,其中下划线表示空字符,空格则为单词之间的分隔。因此这个输出通过空格来分割,然后将连续相同的字符合并为同一个字符,再去掉空字符,就可以得到输出的句子。
2. 触发字检测
许多电子设备可以通过语音唤醒,例如:

实现方法如下图所示:
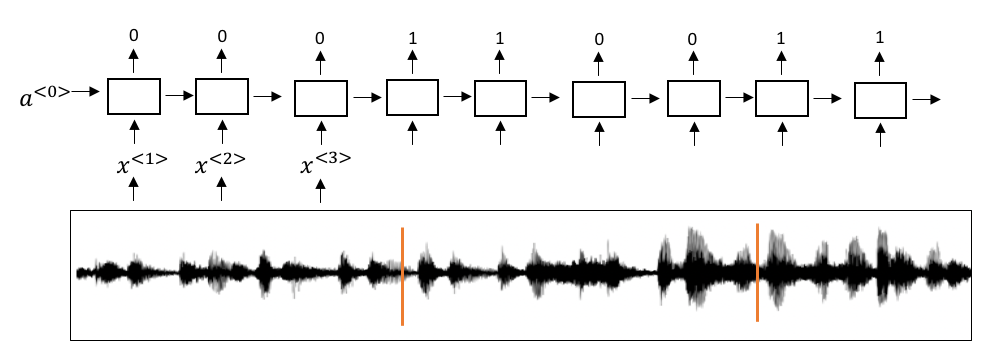
使用一个RNN,对于触发字,标记为1,对于音频的其它部分,标记为0。然后进行训练。