Appearance
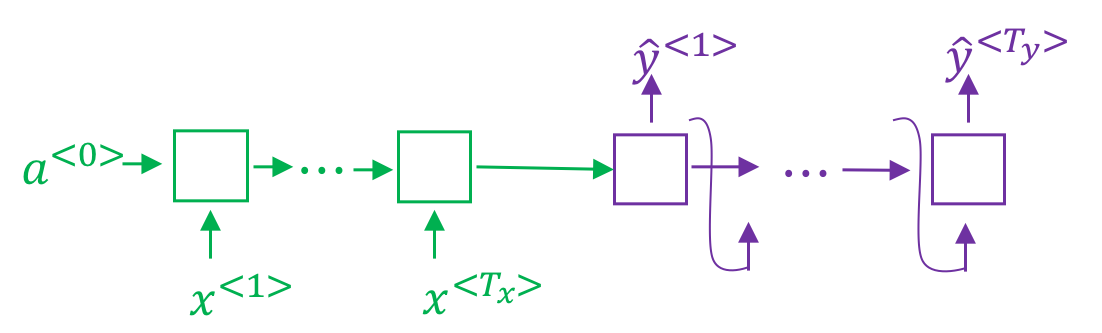
在之前的机器翻译过程中,我们使用如上图所示的编码/解码网络,其中绿色部分会编码整个输入的句子,生成一个编码,然后紫色部分会对其进行解码。
假如要翻译一个很长的句子,那么人工翻译是不会先通读整段句子,然后再一次性进行翻译。而是会一部分一部分进行翻译。因此上图所示的网络结构在处理长句子的时候存在着不足。
注意力模型(Attention Model)正是用来解决这种问题的,相关论文参考 Neural Machine Translation by Jointly Learning to Align and Translate。
如下图所示为注意力模型的简要描述:
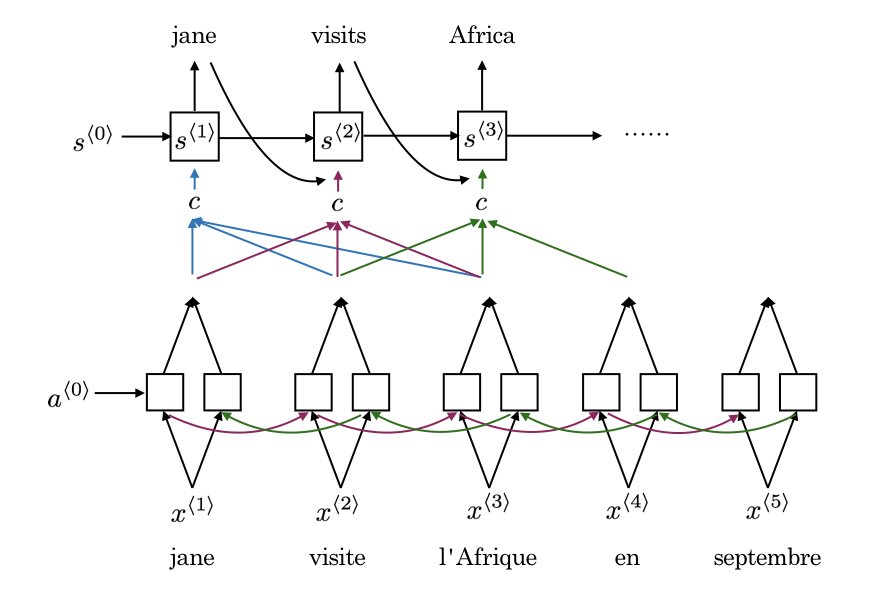
下半部分是一个BRNN,用于计算单词的特征;上班部分为另一个RNN,用于翻译。在翻译第一个词的时候,会考虑原文第一个词以及附近的其它词语。依次类推。
其中