Appearance
1. Sequence to Sequence
例如语言翻译:
- 输入:Jane visite l'Afrique en septembre. 即
- 输出:Jane is visiting Africa in September. 即
为了实现这个过程,首先实现一个编码网络(Encoder Network),将输入的句子编码为一个向量;然后通过一个解码网络(Decoder Network),来输出翻译后的句子。如图所示:
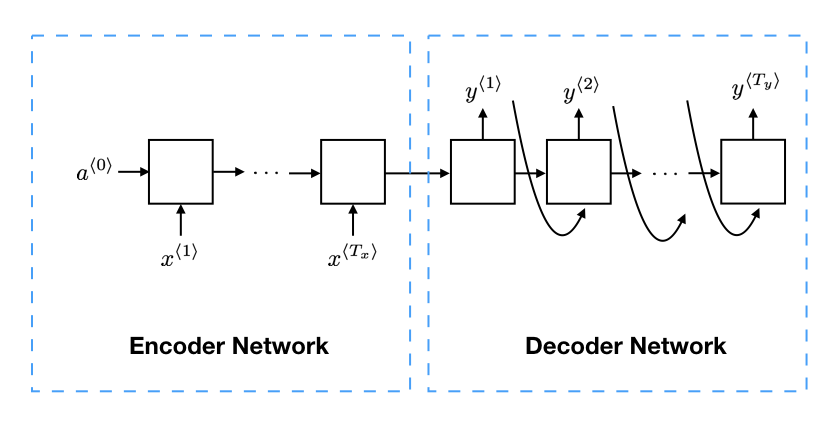
相关论文参考:
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
2. Image Captioning
即看图说话,给一张图片,然后输出对应的文字描述。例如下面的图片:

文字描述为:A cat sitting on a chair.
实现过程与上面翻译的例子相似。只不过首先是通过CNN作为编码网络来得到一个向量,然后通过类似的解码网络输出描述文字。
3. Beam Search
(1)算法
通过前文讲解,我们已经知道在机器翻译工程中,使用了一个编码网络和一个解码网络。如图所示:
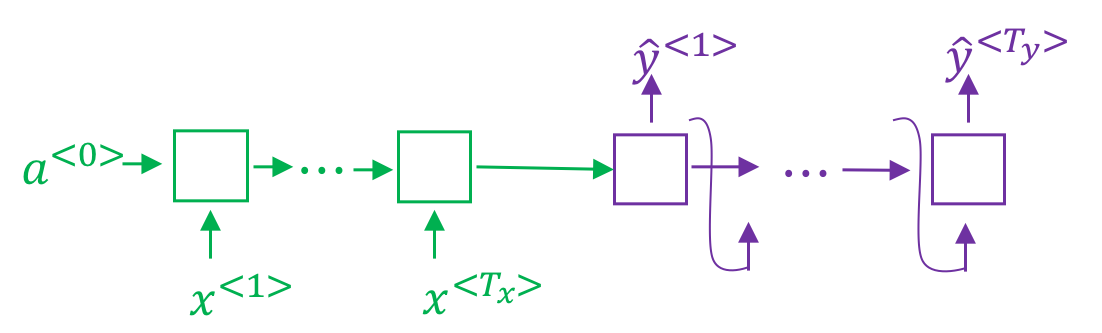
这个网络结构与之前的语言模型非常相似,只不过语言模型只有解码网络这部分,并且其输入是一个零向量。因此可以任务机器翻译使用的是一个条件语言模型,即在给定条件(输入的句子)的情况下的语言模型。因此最终计算的其实是:
给定一句原文,翻译的结果可能有多个,例如原文为:Jane visite l'Afrique en septembre. 翻译结果可能为:
- Jane is visiting Africa in September.
- Jane is going to be visiting Africa in September.
- In September, Jane will visit Africa.
- Her African friend welcomed Jane in September.
那么如何选择最合适的译文呢?其实就是求:
因此需要有一个算法来最大化这个条件概率。在这个场景中,常使用的是 beam search 算法,算法过程如下:
首先选择译文的第一个单词
第一个单词选定之后,就要开始选择第二个单词。由于第一个单词有三个选择,词典一共有10000个单词,因此此时一共有30000个组合。我们需要选取最大的三个
在选取了前两个单词的基础上,再去选择第三个单词。依次类推。如果设置了
越大,可选的结果就越多,越有可能得到最好的结果,但是计算量也随着增大 越小,可选的结果就越少,最终的结果可能不是最好的,但是算法运行会快一些
在实践中,根据应用不同,会选择不同大小的
(2)Length Normalization
在实际使用过程中,会对目标函数做一些调整。考虑到 beam search 最终求的是:
即:
但是由于
但是这样依然存在着一个缺点,即由于
其中
- 当
时,相当于没有做归一化处理 - 当
时,相当于用译文长度来做归一化 - 大多数情况下,
(3)误差分析
Beam Search 是一种近似搜索算法(区别于BFS、DFS这样的精确搜索),或者说是启发式搜索算法,它并不总是输出最好的结果。因此需要通过误差分析来判读是RNN模型(编码和解码)导致的误差还是由于Beam Search算法导致的误差。
例如下面的例子(机器翻译效果不如人工翻译):
- 原文:Jane visite l'Afrique en septembre.
- 人工翻译:Jane visits Africa in September. (
) - 机器翻译:Jane visited Africa last September. (
)
通过计算
- 如果
,则说明 Beam Search 算法没有能够选出最好的结果,因此是 Beam Search 算法出了问题 - 如果
,则说明 RNN 对差的翻译给了更好的概率值,因此是 RNN 模型出了问题
如果对目标函数应用了长度归一化,那么应当将应用了长度归一化的值进行比较。
在实际过程中,会对多个样本进行误差分析,然后统计 RNN 和 Beam Search 造成的错误比例,然后对出错更多的那部分进行优化。
(4)BLEU得分
另一个问题是,在翻译过程中,可能会有多个同样好的结果,那么应该如何衡量准确性呢?例如下面的例子:
- 原文:Le chat est sur le tapis.
- 参考译文1:The cat is on the mat.
- 参考译文2:There is a cat on the mat.
- 机器翻译1:the the the the the the the.
- 机器翻译2:The cat the cat on the mat.
BLEU的理念是,观察机器翻译的结果,看生成的词是否出现在至少一个参考译文中。BLEU需要首先计算:
其中:
表示译文中的 元组,例如对于机器翻译2: : the, cat, the, cat, on, the, mat : the cat, cat the, the cat, cat on, on the, the mat
表示 在译文中出现的次数 表示 在参考译文中出现的最大次数
例如对于参考译文1,
| $ngram$ | $count(ngram)$ | $count_{clip}(ngram)$ |
|---|---|---|
| the cat | 2 | 1 |
| cat the | 1 | 0 |
| cat on | 1 | 1 |
| on the | 1 | 1 |
| the mat | 1 | 1 |
最终的BLEU得分计算为:
其中
相关论文参考 BLEU: a Method for Automatic Evaluation of Machine Translation.