Appearance
1. 序列模型的例子

2. 符号定义
例如一个识别人名的模型,输入
| Harry | Potter | and | Hermione | Granger | invented | a | new | spell | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | |
表示第 个样本的输入 表示第 个样本的输入的第 个位置 表示第 个样本的输出 表示第 个样本的输出的第 个位置 表示第 个样本的输入的序列长度 表示第 个样本的输出的序列长度
那么如何表示一个句子里的一个单词呢?首先需要一张词汇表,例如:
然后对每样本句子中的每一个单词使用 one-hot 方式来表示。
3. RNN
RNN的基本结构如下图所示,可以看到,每一个时刻
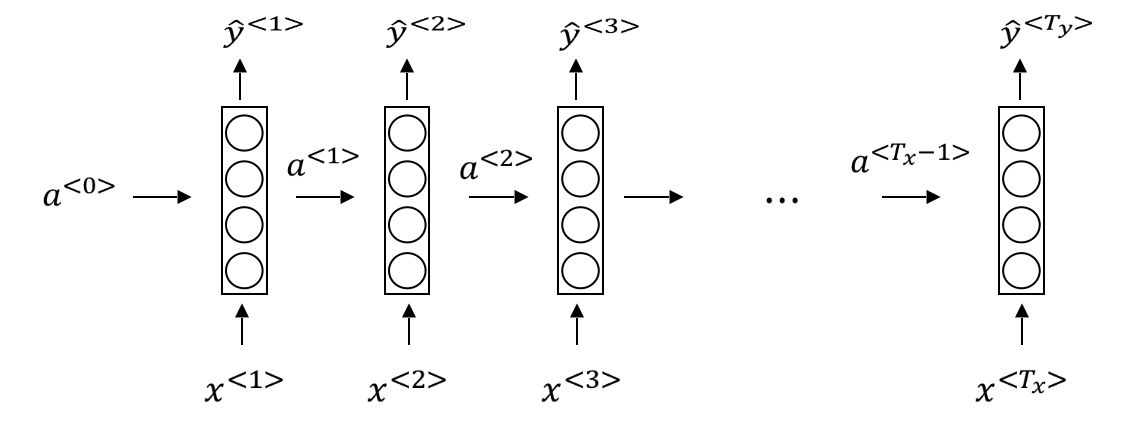
在每个RNN单元内,计算如下:
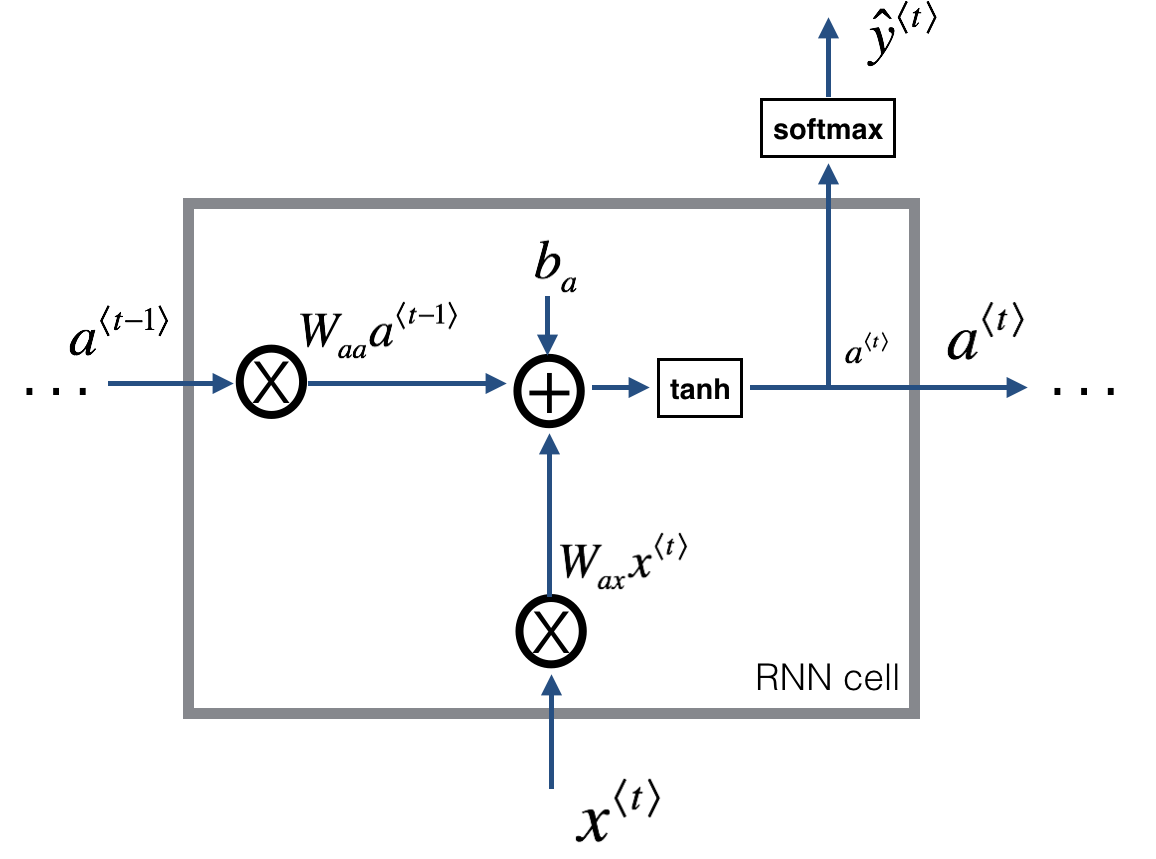
即:
第一个式子里,激活函数通常为
可以令:
因此上面的式子可以简化为:
在反向传播过程中,每个RNN单元内的计算如下图所示:
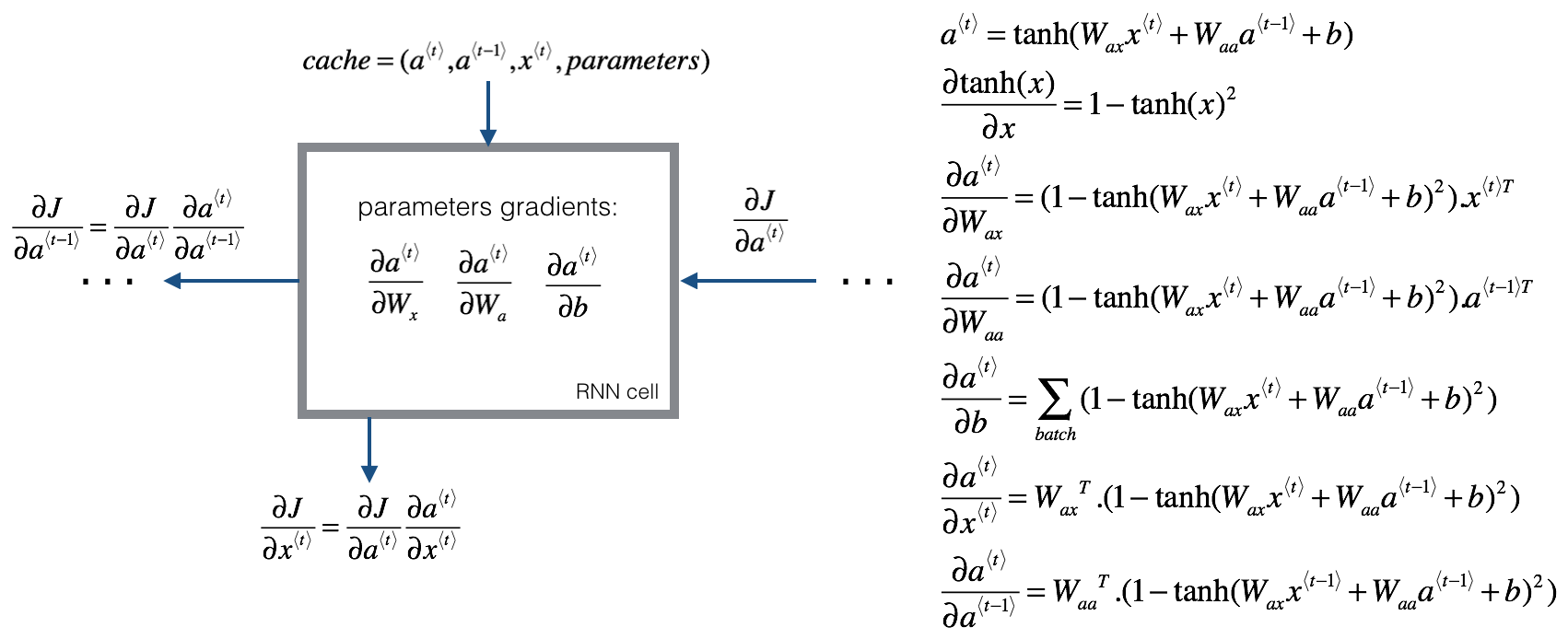
4. 不同类型的RNN
RNN根据实际场景,有着不同的结构。如下图所示:
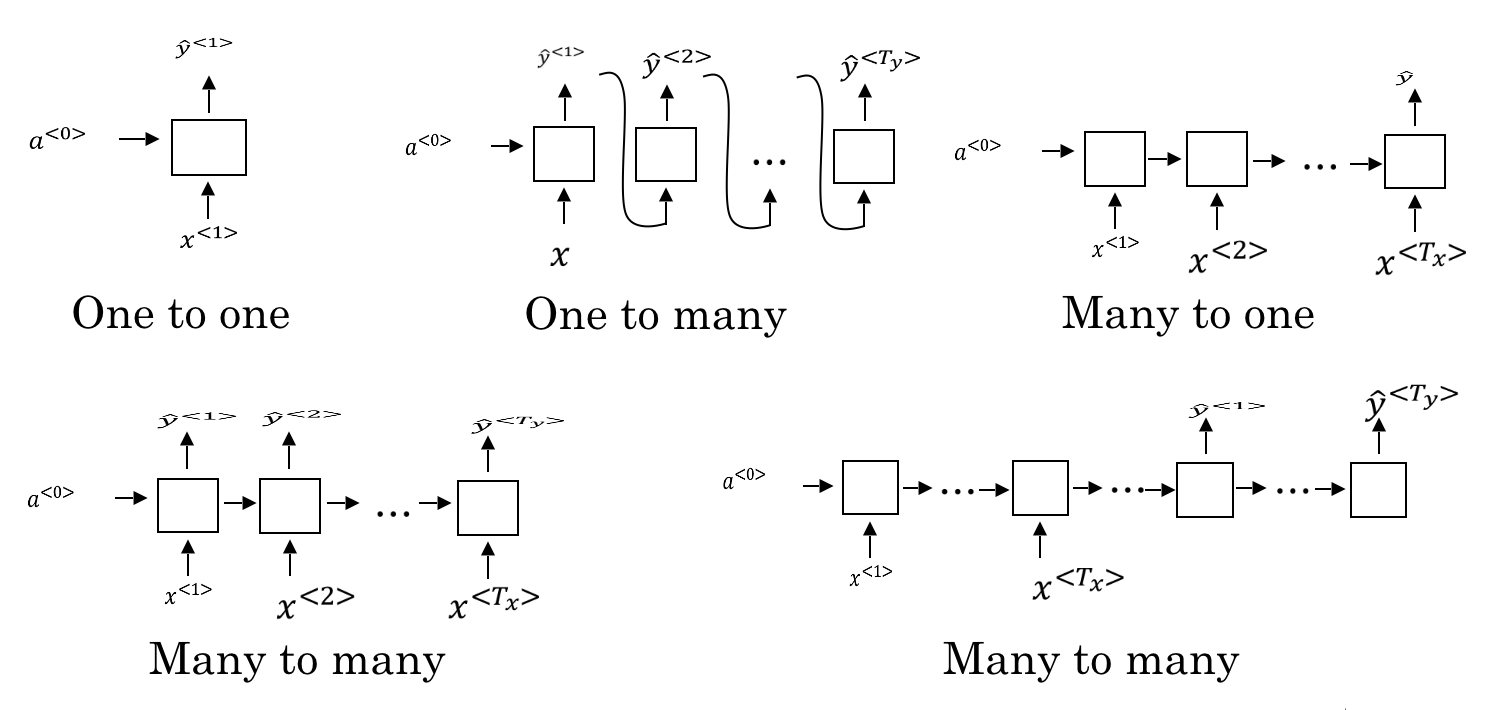
- one-to-one:即普通的神经网络
- one-to-many:序列生成。例如根据一个输入(音乐流派,第一个音符,或者空值)生成一段音乐
- many-to-one:例如对影评进行评分;分析文本的情感倾向灯
- many-to-many (
):例如上文提到的判断一句话里哪些单词是人名 - many-to-many (
):例如语言翻译
5. 语言模型
常用于语音识别和机器翻译。例如两句话:
- The apple and pair salad.
- The apple and pear salad.
语音识别系统可能会认为用户说的更有可能是第二句话。事实上,在选择的过程中,其实是计算了每句话的概率,从而选取可能性大的那句话。语言模型要做的就是判断一个句子出现的概率,即
为了构建语言模型,需要有一个很大的语料库(corpus)作为训练样本。假设语料库中有一个句子是:Cats average 15 hours of sleep a day. 那么需要做的是:
针对句子中的每一个单词,根据词典来得到其 one-hot 的向量化形式
- 标点符号可以自行决定要不要作为一个token
- 如果字典中没有该单词,则使用一个特殊标记
来表示(UNKNOWN)
增加一个特殊标记
,表示句子的结尾(可选,根据需求而定) 构建RNN网络来进行训练
计算的是 ,即 cat 作为句子第一个词出现的概率; 计算的是 ,即在 cat 是句子开头的情况下,average 是第二个单词的概率;依此类推
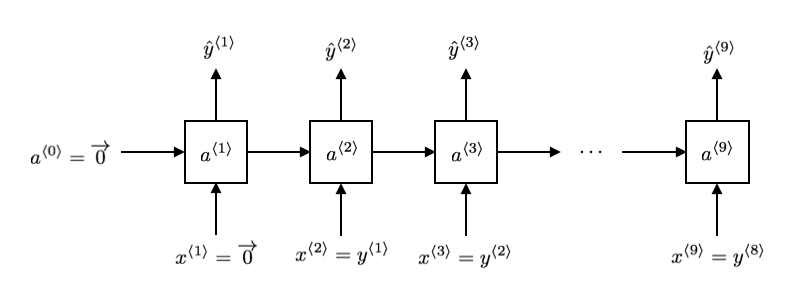
训练完成之后,假设有一个句子有三个单词
6. 新序列采样
训练序列模型过程中网络结构如下图所示:
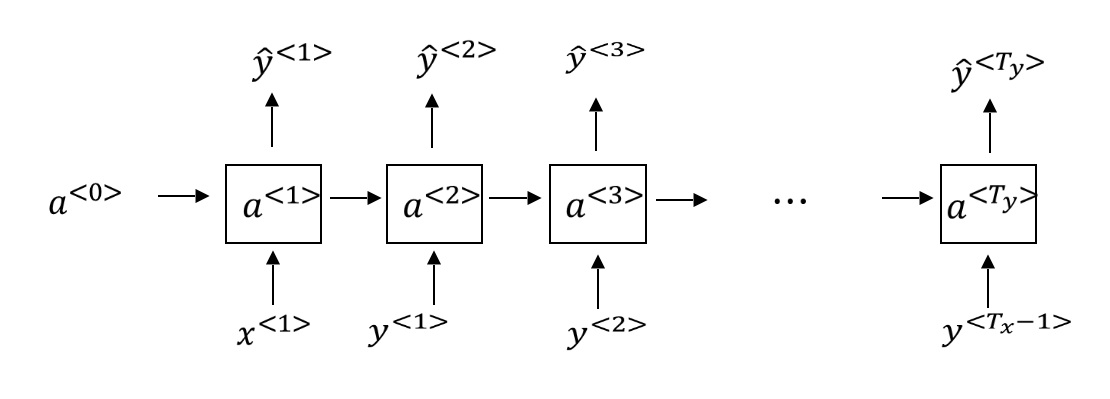
在训练好了一个序列模型后,要想知道这个模型学到了什么,可以进行一次新序列采样,从而生成一段随机的序列。在对新序列采样过程中,网络结构有一些不同,如下所示:
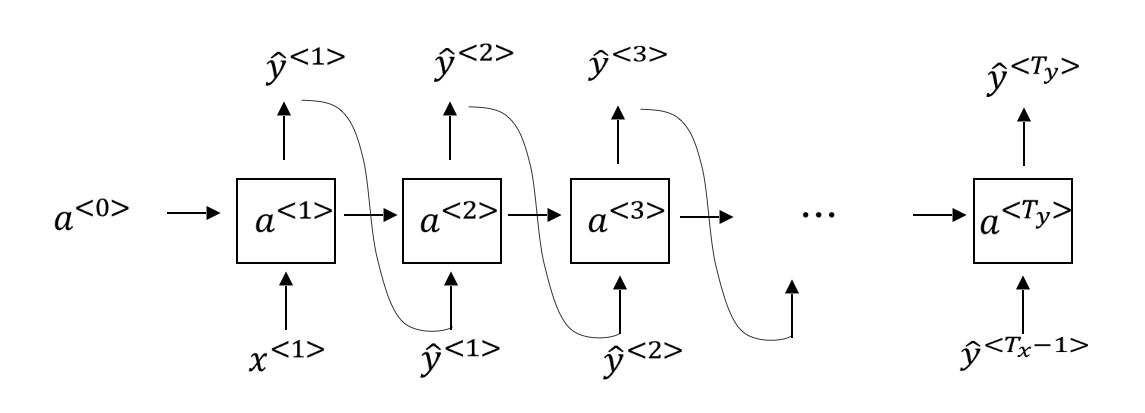
- 通过输入
和 ,得到 ,然后通过 numpy.random.choice进行采样作为句子第一个单词。 - 然后将
作为输入,得到 ,然后通过采样得到句子的第二个单词。 - 依此类推,生成一个完整的句子。
- 结束条件:限定序列的长度或者遇到
- 生成过程中遇到
,根据需要直接使用,或者忽略然后继续采样
- 结束条件:限定序列的长度或者遇到
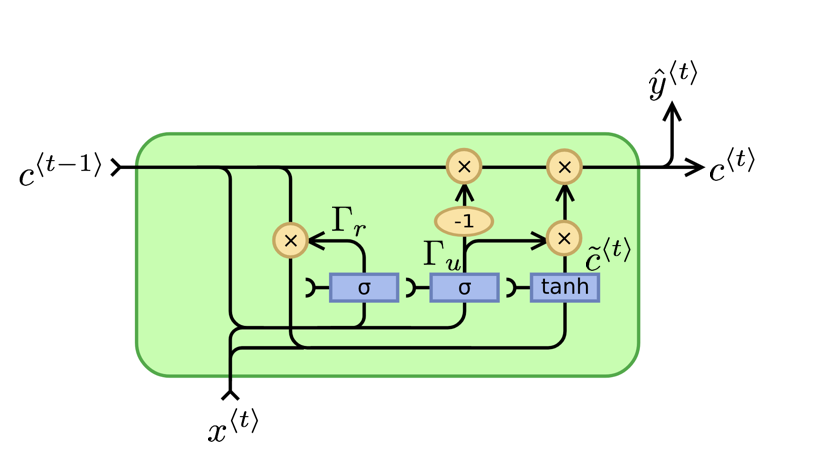
7. GRU单元
相关论文:
- On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
- Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
上面介绍的基础的RNN只能处理临近依赖,而无法有效地处理长期依赖。例如下面两个句子:
- The cat, which already ate …, was full.
- The cats, which already ate …, were full.
后面是 was 还是 were,依赖于前面是 cat 还是 cats。
GRU (Gated Recurrent Unit,门控循环单元) 可以更好地捕获深层连接,处理长期依赖,并且改善了梯度消失的问题。
8. LSTM
LSTM (Long Short Term Memory,长短期记忆) 单元,是另外一种更加强大的RNN单元结构。
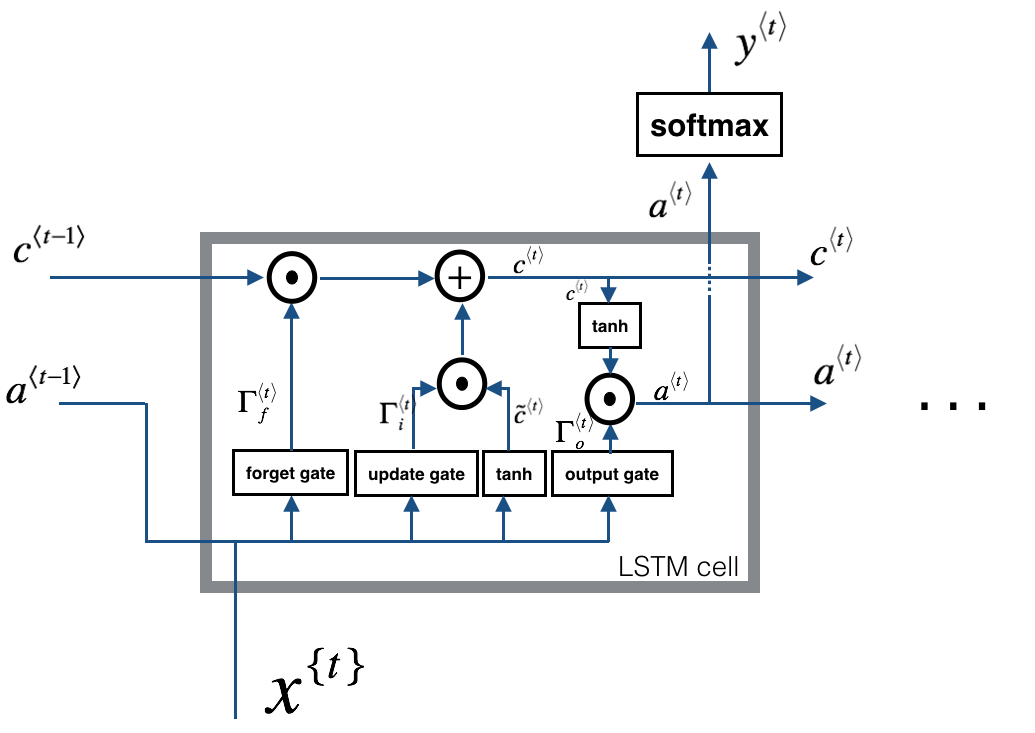
与GRU相比,LSTM有三个门(遗忘门、更新门、输出门),因此更为强大。不过GRU由于结构相对简单,性能相对高一些,可以构建更大规模的网络。
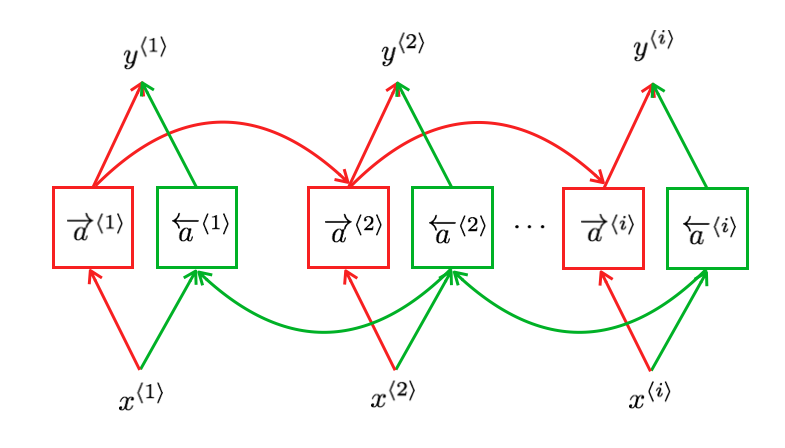
9. BRNN
例如一个识别句子中人名的模型,输入下面两个句子:
- He said, "Teddy bears are on sale!"
- He said, "Teddy Roosevelt was a great President!"
在遇到第三个单词 Teddy 的时候,只看句子前面部分是不够的,还需要句子后半部分的信息。此时需要使用双向RNN (Bidirectional RNN)。如下图所示:
10. 深层RNN
通过增加隐藏层来构建更深的RNN网络。如图所示:
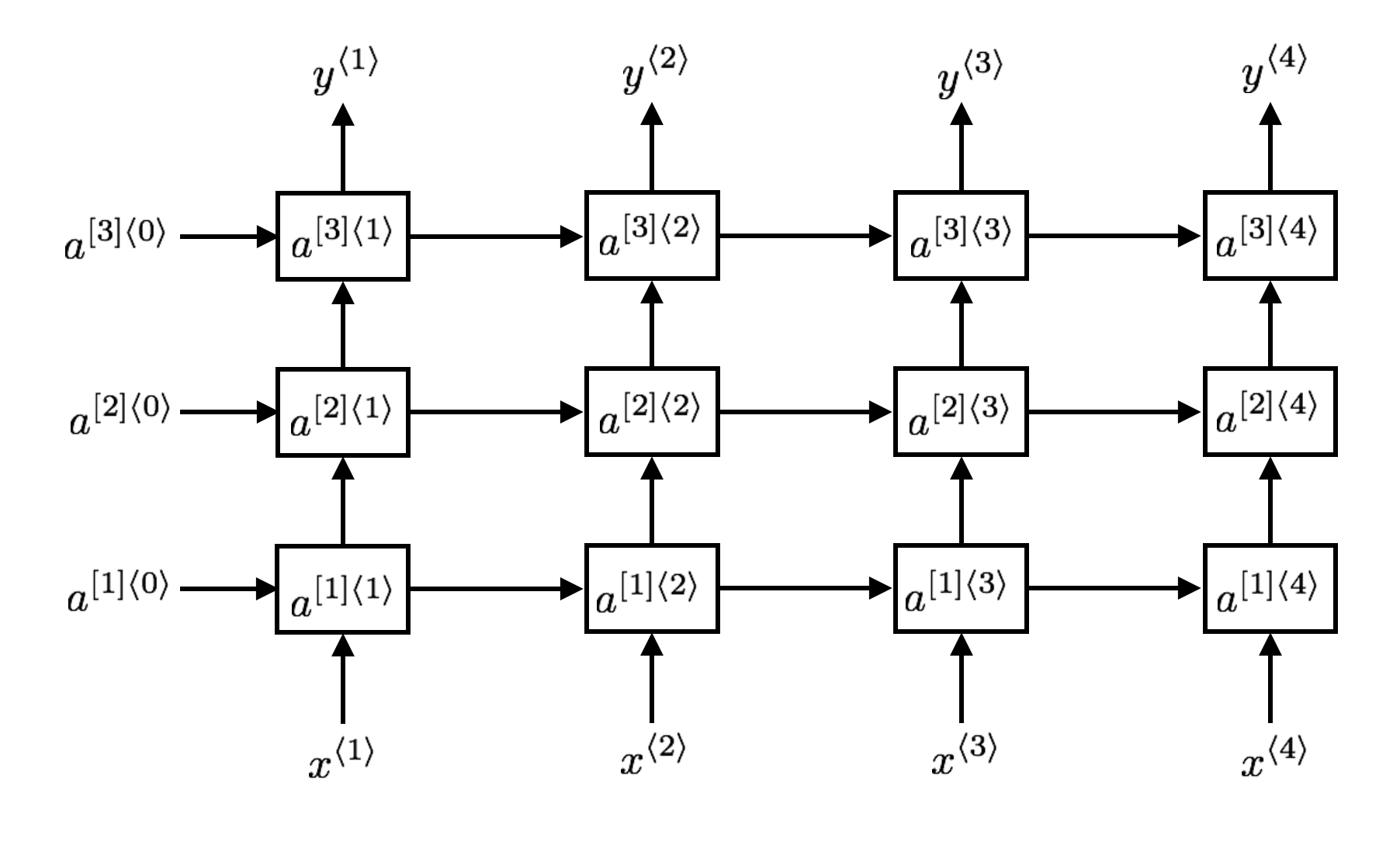
其中每一个单元可以是普通的RNN单元,GRU或者LSTM。