Appearance
1. 人脸验证和人脸识别
- 人脸验证(Face Verification):1对1问题,即输入图片,判断图片是否是正确的那个人(即已经有了一个人的信息)
- 人脸识别(Face Recognition):1对n问题,即输入图片,需要输出对应的那个人信息(即已经有了n个人的信息)
2. One-Shot 学习
对于图像的识别,通常需要大量的标注样本。对于一个企业的人脸识别系统,可能数据库中只有每个员工的一张照片,那么就需要通过这一个样本来进行学习,这就是one-shot learning,即单样本学习。
相似度函数,用
3. Siamese Network
即孪生网络。相关论文可以参考 DeepFace: Closing the Gap to Human-Level Performance in Face Verification
假设有两张人脸的图片
在训练的时候,要对训练样本中的任意一对
4. Triplet 损失

其中:
- A (Anchor)
- P (Positive):正样本,即和Anchor是同一个人
- N (Negetive):负样本,即和Anchor是不同的人
需要满足:
即:
但是这种情况下,如果每张图片的encoding都是一个零向量,则上面的式子总是满足的。因此需要:
定义损失函数:
则整个网络的损失函数为:
那么如何选择这三元组呢?如果是随机选择的话,很有可能A和N的差异会很大,从而导致网络不需要过多学习就可以轻易地进行区分。为了避免这种情况,需要选取
5. 二分类
也可以将人脸识别当做一个二分类的问题。
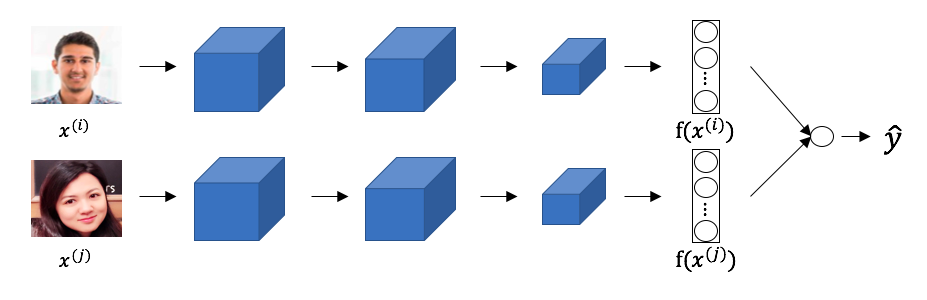
如图所示,两张图片
即将人脸识别当做一个监督学习,将成对的图片作为训练样本。如果两张图片是同一个人,则标签为1;如果两张图片是不同的人,则标签为0。