Appearance
1. 目标定位

- 图片左上角为
,图片右下角为 - 目标中心点为
,宽度为 ,高度为
假设要识别的目标有三类:
- 行人
- 汽车
- 摩托车
则:
其中
如果图片中没有检测到需要识别的对象,则表示为:
损失函数可以表示为:
这里使用平方差简化了流程,实际上,可以针对
2. 滑动窗口
检测图片中的对象,可以通过滑动窗口的方式。即定义一个固定大小的窗口,在图片区域上滑动。对每个区域分别进行检测。
为了在卷积网络中使用滑动窗口,首先要将全连接层转换为卷积层。如图所示:
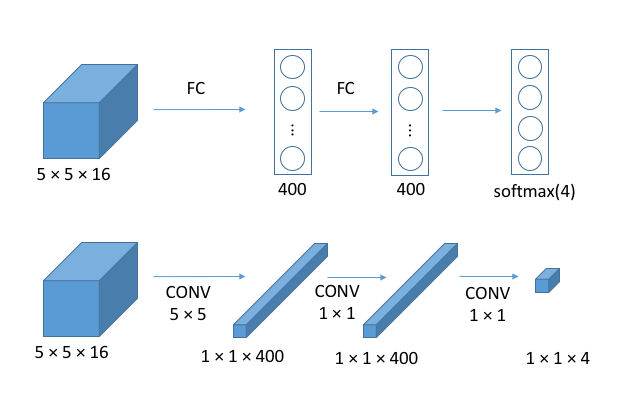
在应用滑动窗口的过程中,不是每个窗口单独去计算的,而是一次性计算多个窗口,这样许多计算都是可以共享的,如下图所示:

上半部分是针对一个窗口的计算,下面是同时计算了四个窗口,每个窗口大小为
该部分内容可以参考论文OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks。
滑动窗口的卷积实现,虽然计算效率高,但是也存在着显而易见的缺点,即由于窗口大小和滑动步长的原因,窗口不一定正好匹配需要检测的对象,因此不能够输出精准的边界框。
3. YOLO
论文参考You Only Look Once: Unified, Real-Time Object Detection。

如图所示,将图片分成一个个网格,对每个格子应用目标定位算法。针对每一个格子,其标签形式都是:
在上图中,一共有两个目标,选取这两个目标的中心点,将这两个目标分别分给包含其中心点的格子。然后针对每一个格子,将其坐标归一化到
4. IOU
IOU(Intersection Over Union)即交并比,即计算两个边界框的交集和并集之比,如图所示:

对检测出的边界框和实际的边界框求IOU,一般认为大于等于0.5的时候,检测是正确的。
5. Non-Max Suppression
缩写NMS,即非极大值抑制。在进行目标检测的时候,可能会对同一个目标检测多次,如图所示:
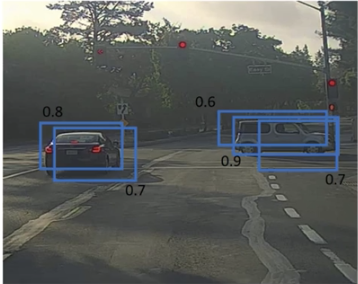
该算法用于保证对同一只对象只检测一次。算法流程是:
- 设定
,舍弃所有 - 针对剩下的所有边界框,选择
最大的,作为一个预测输出;并且把所有与这个边界框 的边界框都舍弃 - 重复第二步的过程
6. Anchor Box
在上面介绍的算法中,一个网格只能检测出一个对象,但是有些情况下,可能多个对象都会落到同一个网格中,如图所示:

预先定义一些 anchor box 的形状,例如:
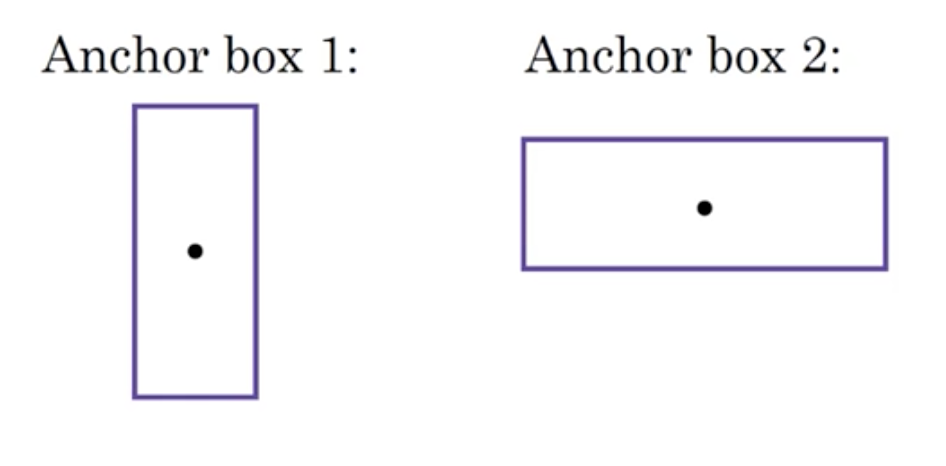
然后
其中上半部分表示 anchor box1,下半部分表示 anchor box2。因此图中的格子可以表示为: