Appearance
1. BGD
BGD即批量梯度下降(Batch Gradient Descent),是最原始的梯度下降形式,即每次使用所有训练样本来进行梯度下降。
优点是得到的是全局最优解。
缺点是在样本数量较大的情况下,BGD会运行的很慢。
2. SGD
SGD即随机梯度下降(Stochastic Gradient Descent),即每次使用一个样本来进行梯度下降。
优点是训练速度会比较快。
缺点是在样本数量较大的情况下,可能只用到了其中一部分数据就完成了训练,得到的只是全局最优解。另外,单一样本的噪声较大,所以每次执行梯度下降,并不一定总是朝着最优的方向前进。
SGD和BGD的优化过程比较如下图所示:
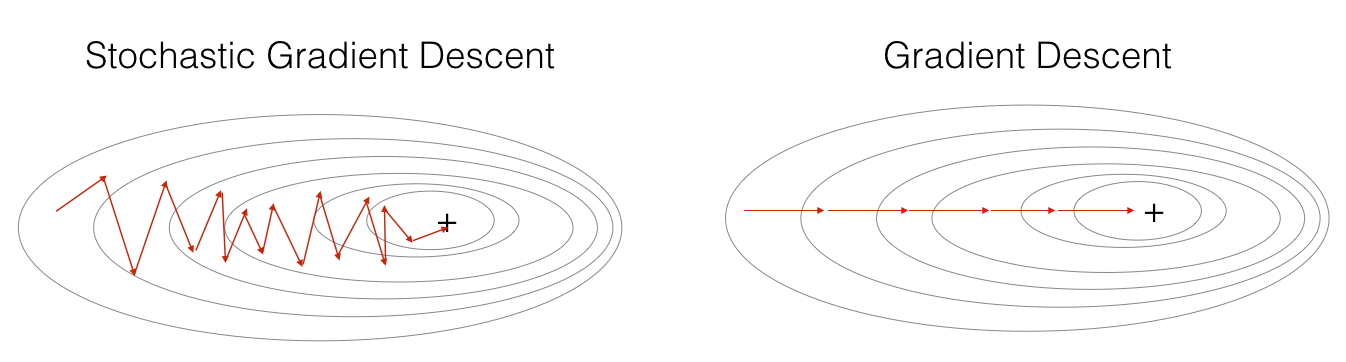
3. MBGD
MBGD即小批量梯度下降(Mini-Batch Gradient Descent),它是BGD和SGD的折中,即每次使用一部分的样本来进行训练。
批量大小的选择遵循以下原则:
- 如果数据量较小,直接使用BGD,即
- 数据量较大的情况下,一般
为64到512之间,并且设置成2的次方会好一些,如64、128等 - 还要考虑机器的GPU/GPU开销
MBGD和SGD的优化过程比较如下图所示:
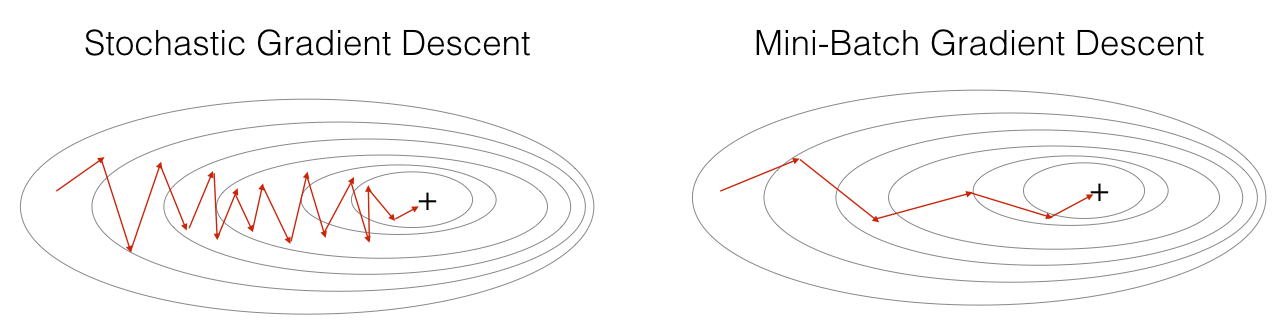
4. 指数加权平均
指数加权平均(Exponentially weighted averages)是一种对数据的处理方法,在之后要介绍的的优化算法中,用到了该方法。
假设有一组数据
则此时
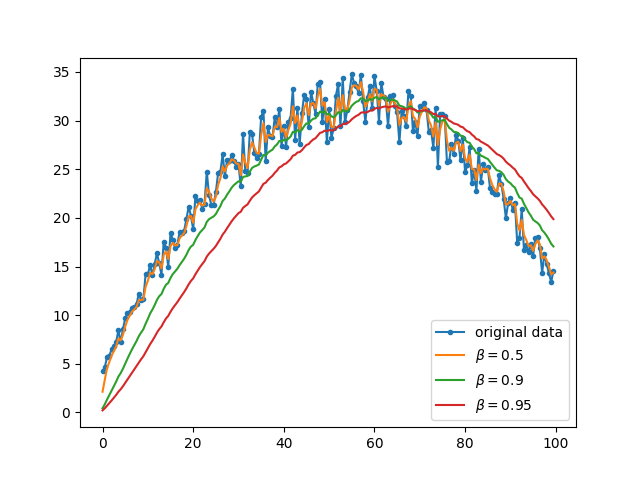
越大加权平均后的数据越平缓,极端情况 为0,则等于原始数据 表示的是平均的是最近的数据数量,例如 ,则表示加权平均后的每条数据是由原始数据的10条数据平均而得到
但是考虑到假如
效果如图所示:
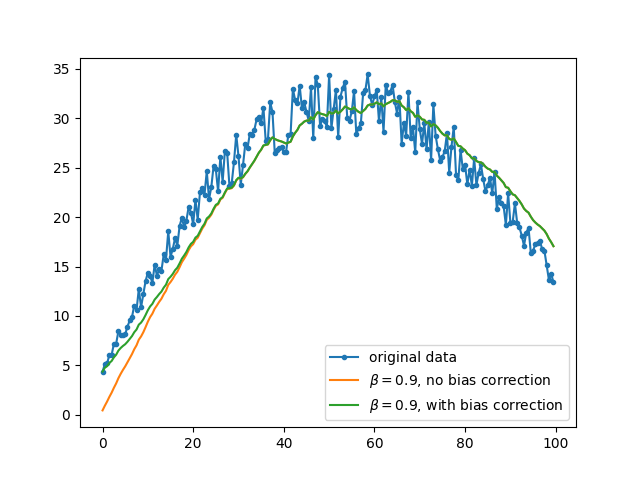
可以看到,在初期,偏差修正后的数据表现更好;在后期,两条线基本重合。
5. Momentum
过程如下:
- 初始化
- 在每次迭代中,计算出当前mini-batch的
其中
Momentum的效率通常要好于不适用Momentum,通过上面的过程可以发现:本次梯度下降的数值是一个加权平均,因此如果本次梯度下降的方向与上次方向相反,上次的更新会对本次有一个减速的作用例如过本次梯度下降的方向与上次方向相同,则上次的更新会对本次有一个正向的加速作用。
如图所示,不适用Momentum的时候,梯度下降如蓝色线条所示;使用了Momentum的时候,梯度下降如红色线条所示。

6. RMSprop
全称为 Root Mean Square Prop,同样可以加速梯度下降。过程如下:
- 初始化
- 在每次迭代中,计算出当前mini-batch的
7. Adam
Adam优化算法是将Momentum和RMSprop结合起来。过程如下:
- 初始化
- 在第t次迭代中
- 计算出当前mini-batch的
- 计算
- 偏差修正
- 更新
,其中 为一个很小的数,通常取 ,是为了防止分母为0
- 计算出当前mini-batch的
该算法中涉及到了以下几个超参数:
:需要调整 :通常取0.9 :通常取0.999 :通常取
通常会使用默认的
在梯度下降过程中,由于每一个mini-batch都会存在着一定的噪音,因此最终会在最优点附近左右摆动。换言之,在优化初期,可以使用较大的学习速率,但是之后如果继续使用较大的学习速率,会导致在最优点附近的摆动较大;因此随着训练的进行,可以使用较小的学习速率,从而减小在最优点附近的摆动幅度。
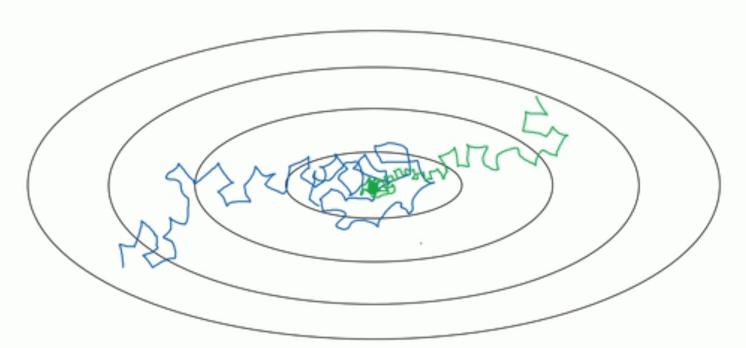
如图,在不使用学习率衰减的情况下,优化过程如蓝色线条所示;使用了学习率衰减的情况下,优化过程如绿色线条所示。
每遍历一遍训练集为一个epoch,则:
另外还有:
, 是一个常数 , 是一个常数, 为迭代次数 - 离散的学习率